Maskininlärning inom utbildning
Abstract
Machine learning has revolutionized the way we approach problem solving. The technique’s high adaptivity has led to implementations in many fields including medicine, autonomous vehicles and economics, where classic mathematical methods are not enough. The purpose of this paper is to evaluate the impact of Sana Labs “Sana Learn” algorithm on learning words from a foreign language. The test was conducted through a quiz web app that was specifically developed for this study. Members of group “machine learning” were provided quizzes with questions chosen by Sana Learn, tailored to their individual learning curves. The control group were provided quizzes with questions selected randomly. The results showed that group “machine learning” on average performed better than the control group in almost every metric. The results are however disputable because group “machine learning” covered a smaller percentage of the learning material than the control group.
Inledning
Konceptet artificiell intelligens har funnits sedan 1940-talet och föddes ur en handfull matematiker och filosofers gemensamma idé att replikera den mänskliga hjärnan med hjälp av matematik och logik. Idén tog fart ordentligt när datorpionjären Alan Turing publicerade sin vetenskapliga rapport ”Computing Machinery and Intelligence”. I rapporten resonerar Turing omkring hur våra synapser överför och behandlar information med liknande elektriska signaler som datorer använder för att behandla binär data och logiska portar. I rapporten formulerar även Turing det nu välkända ”Turing” testet, ett test som utreder om ett datorprogram har nått nivån för att räknas som en artificiell intelligens.
Turing var begränsad av tekniken från hans tid och hann avlida innan området han lagt grunden för vidareutvecklades. Ny teknik och matematiska modeller skapade lösningar för problem som dömts olösbara av klassiska matematiska metoder. Sen början av 1990-talet har området haft flera stora genombrott:
-
Gary Kasparov, världsmästare i schack förlorade år 1996 mot IBM:s artificiella intelligens Deep Blue.
-
IBM:s Watson besegrade år 2011 två ”mästare” i live frågesportprogrammet ”Jeopardy!”, Ken Jennings och Brad Rutter.
-
År 2018 förlorade kinesiska GO mästaren Ke Jie mot Google DeepMinds AlphaGo. En jämn match som pressade AlphaGo till sitt yttersta enligt Google DeepMinds grundare Demis Hassabis.

Bild 1:Ke Jie spelar det kinesiska brädspelet GO mot den artificiella intelligensen Alpha GO
Bakgrund
Artificiell intelligens och Maskininlärning
Termerna AI (Artificiell Intelligens) och maskininlärning betraktas och används av många som synonymer även fast de har olika distinkta betydelser:
Artificiell intelligens: en akademisk disciplin med målet att skapa maskiner/datorsystem som utför uppgifter som anses vara mänskliga, som kräver en intelligens. Till exempel komponera musik eller kommunicera med språk.
Maskininlärning: en grupp tekniker inom artificiell intelligens där målet är att skapa algoritmer som efterliknar hur vi människor lär oss.
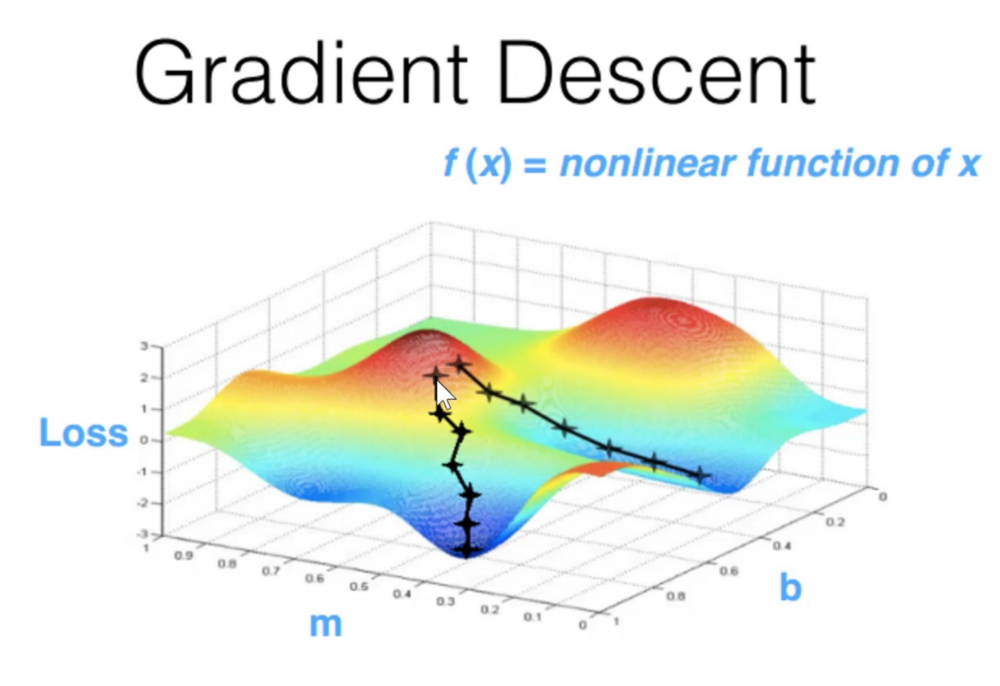
Ett bra exempel på en simpel maskininlärnings algoritm är linjär regression. Målet med linjär regression är att skapa en linjär funktion som matchar markerade data så precist som möjligt för att fortsätta beskriva ett samband.
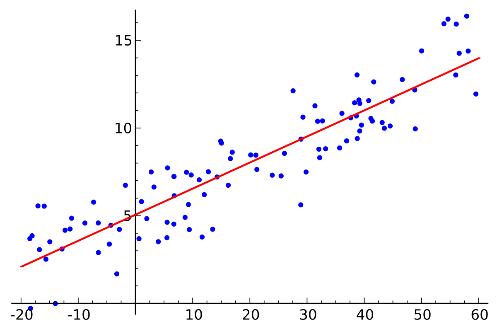
Bild 2: Exempel på linjär regressionsanalys
Artificiella intelligenser som baseras på maskininlärnings algoritmer är specialiserade. Det betyder att de inte kan överföra deras lärdomar till andra problem. För att komma runt detta bygger man ofta ett nätverk utav flera mindre specialiserade algoritmer.
Deep Learning/Neurala Nätverk: en maskininlärningsmodell där målet är att uppnå inlärning igenom att efterlikna hjärnans synapser. Deep Learning neurala nätverk tränas på stora datasett för att identifiera korrelerande variabler och mönster (se Bild 3), vilket nätverket senare använder som grund för att göra sina förutsägelser om annan data.
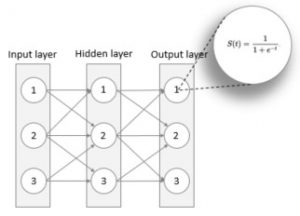
Bild 3: Diagram över ett neuralt nätverk
Rekommendationssystem
Rekommendationssystem är matematiska algoritmer som är utformade för att rekommendera anpassat innehåll till användare. De vanligaste algoritmerna för rekommendationsproblem kombinerar matrisfaktorisering och maskininlärningstekniker som neurala nätverk. Det tre vanligaste rekommendationsstrategierna är, innehållsbaserad, kollaborativbaserad och hybridfiltrering.
Innehållsbaserad: rekommenderat innehåll baseras på tidigare innehåll användaren har interagerat med. Till exempel liknande produkter till något användaren tidigare sökt efter.
Kollaborativbaserad: rekommenderat innehåll baseras på relationen mellan olika användare och innehåll. Till exempel produkter andra användare har köpt i samband med en specifik produkt .
Hybrid: hybridsystem blandar innehållsbaserade och kollaborativbaserade strategier för att skapa en relation mellan både innehåll, användare och deras interaktioner. Till exempel streamingtjänster för musik, där rekommendationer baseras både efter vad användare med liknande musiksmak lyssnar på och efter hur användaren betygsätter systemets rekommendationer .

Bild 4: Exempel på ett rekommendationsproblem som kan lösas med hjälp av matrisfaktorisering (Serrano, 2018).
Matrisfaktorisering fungerar genom att multiplicera flera matriser tillsammans för att förutspå en poäng, denna poäng används för att sortera innehållet och sedan ta fram rekommendationer. Analysera exemplet i Bild 4, person A, B, C och D beskrivs i en matris ovan där kolumnerna beskriver om personen gillar en viss genre. Detta kan representeras i en matris binärt som en etta eller en nolla.
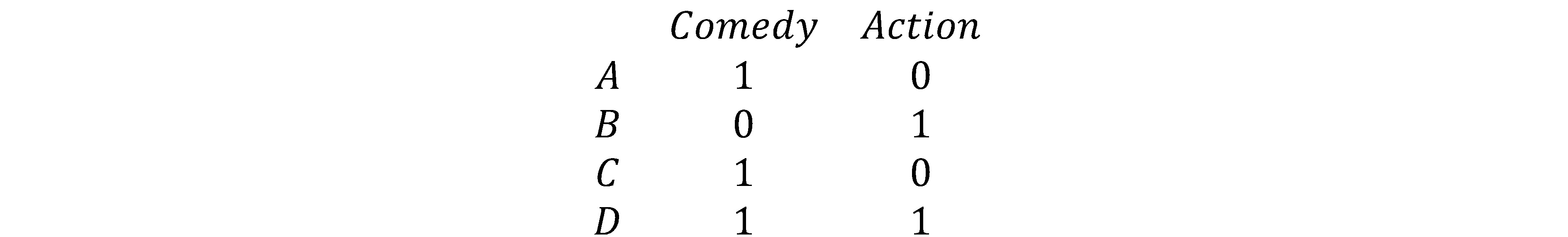
Filmerna i detta exempel beskrivs också som en matris, där raderna beskriver hur mycket en genre beskriver filmerna i kolumnerna. Detta kan representeras med matrisen:
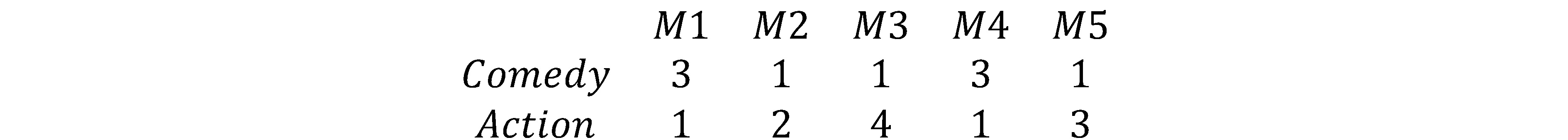
Med dessa två matriser kan man förutspå en ”rekommendations” matris, igenom att multiplicera
båda matriserna ovanför . Detta ger:

Med denna matris kan vi för varje användare, som representeras av en rad, sortera kolumnerna i storleksordning och sedan välja de högst rangordnade filmerna att rekommendera till användaren.
Sana Labs
Sana Labs är ett teknikföretag som utvecklar maskininlärningsstödda lösningar för att underlätta utbildning. Sana Labs ”Sana Learn” rekommendationssystem är utformat för att rekommendera optimala frågor för den individuella elevens inlärningskurva baserat på elevens tidigare svar, betänketid och svårighetsområden.
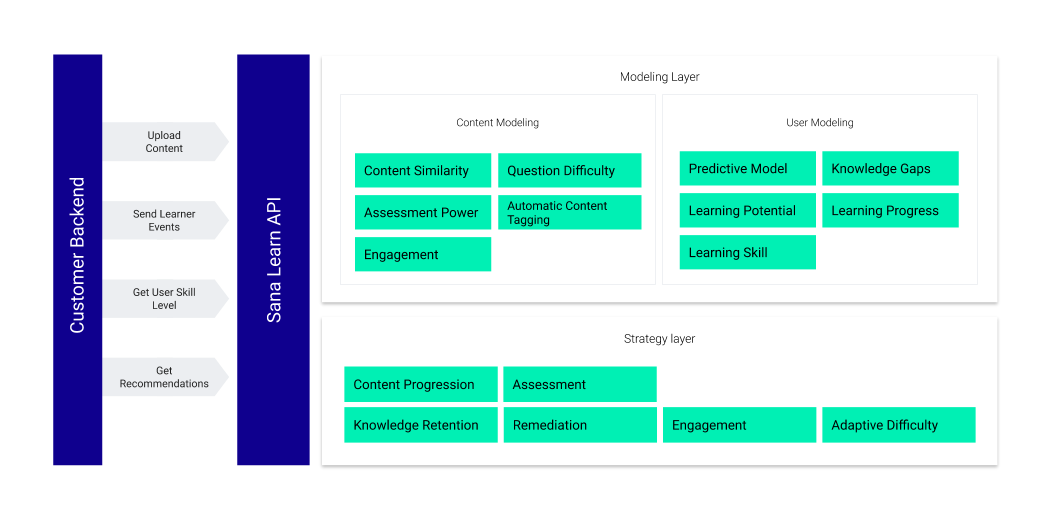
Bild 5: Överblick över den tekniska strukturen hos ”Sana Learn”
Exakt hur rekommendationssystemet är uppbyggt är okänt, då Sana Learn är stängd källkod, men en översikt av systemets komponenter (se Bild 5) är tillgänglig på Sana Labs hemsida i deras tekniska dokumentation. Från den tekniska dokumentationen ser vi att Sana Learn är ett hybridsystem som baserar sina rekommendationer på innehållets egenskaper (Content Modeling), användarens egenskaper (User Modeling) och interaktionerna mellan användare och innehåll (Strategy Layer) .
Syfte
Syftet är att utvärdera Sana Labs ”Sana Learn” algoritms påverkan på inlärning av ord från ett främmande språk, samt undersöka hur stor procentuell skillnad det är mellan slutresultaten för grupp ”maskininlärning” och kontrollgruppen efter 3 veckor.
Frågeställning
Hur ser skillnaden ut mellan testresultaten för de som har maskininlärningsstödd inlärningsmetod gentemot de med slumpmässig inlärningsmetod?
Metod
För att mäta rekommendationssystemets påverkan genomfördes ett glostest på grönländska ord för två undersökningsgrupper, en grupp med stöd av Sana Learn: grupp ”maskininlärning” och en kontrollgrupp utan något stöd. Testen genomfördes med en glostest web-applikation som utformades specifikt till denna undersökning (Se Bilaga 1 och 2). Den mest relevanta delen av webbapplikationens källkod som hanterar användarinteraktioner finns under Bilaga 1.
Deltagarna fick personliga konton som de kunde använda för att logga in med i webbapplikationen. Från webapplikationen kunde användarna genomföra glostest på tio grönländska glosor styck och följa sin personliga utveckling. Användarna blev instruerade att genomföra minst ett test dagligen men tilläts disponera tiden fritt.
Bild 6: Hemskärmen i glostest webbapplikationen “Mimer”.
Deltagarna var trettio volontärer som anmält sig från klasser på en medelstor gymnasieskola i Sverige. Dessa deltagare slumpades sedan in i en av de två undersökningsgrupperna. Grupperna hade en storlek på femton personer vardera och samma genusfördelning, 27% tjejer och 73% killar. Kontrollgruppen fick prov med frågor valda slumpmässigt. Grupp ”maskininlärning” fick prov med frågor valda av Sana Learn, som baserades på den individuella användarens inlärningskurva. Källkoden för kommunikation mellan Sana Learn och glostest webbapplikationen finns under Bilaga 2.
Bild 7: Fråga ur ett prov i glostest webbapplikationen “Mimer”
Testerna utfördes över en tid på 3 veckor och användarnas testresultat sparades i en databas (PostgreSQL se Bilaga 1). Resultaten användes sedan för att utforma en statistisk rapport med en sammanställning av resultaten för de två grupperna.
Resultat
Poängen för testen har normaliserats mellan 0,0 – 1,0 där 0,0 är noll rätt och 1,0 är tio av tio rätt. För båda grupperna sammanfattades användarnas individuella resultat med ett medelvärde för variablerna ”slutgiltig poäng” och ”läromaterialtäckning”. För variabeln ”utförda test” användes en median istället för ett medelvärde.
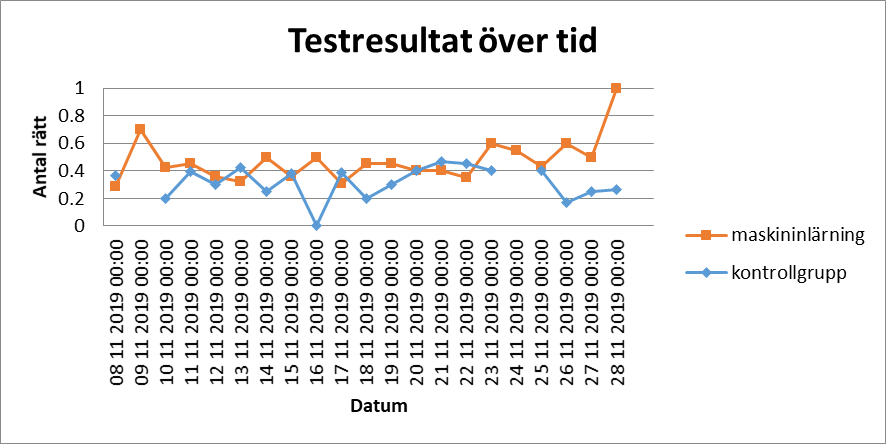
Diagram 1: Gruppernas medelresultat dagligen över tre veckor. Avbrott i grafen betyder att gruppen inte genomförde något test den dagen.
”Läromaterialtäckning” är den procentandel av unika frågor som blivit besvarade av en användare någon gång under testperioden. En lägre procent betyder att användaren har besvarat samma frågor flera gånger istället för flera unika.

Tabell 1: Statistisks sammanfattning för gruppernas resultat.
Inom grupp ”maskininlärning” börjar inlärningskurvan (se Diagram 1) på 0,3 och stabiliserar sig vid 0,4. Det tar till starten av vecka tre innan kurvan börjar öka regelbundet och slutar på 1,0. Den statistiska sammanfattningen (se Tabell 1) för grupp ”maskininlärning” visar att gruppen slutgiltigt hamnade på en medelpoäng av 0,2973. Gruppen utförde en median på fyra test och svarade på ett medelvärde av 27,4% av frågorna.
Grafen för kontrollgruppen har ett större värdeomfång jämfört med grupp ”maskininlärning”. Kontrollgruppen startar med ett medelvärde på cirka 0,35 och stabiliserar sig inte över hela testperioden utan pendlar mellan 0,2 – 0,4. Den statistiska sammanfattningen för kontrollgruppen visar att gruppen hade en slutgiltig medelpoäng av 0,2486, utförde en median av två test och svarade på ett medelvärde 34,5% av frågorna (se Tabell 1).
Diskussion
Resultatdiskussion
Vid analys av resultaten är det viktigt att ha i åtanke hur de olika två grupperna blev tilldelade sina frågor. I en jämförelse av slutresultaten för båda grupperna så slutade grupp ”maskininlärning” med en högre slutpoäng och genomförde i snitt flera test än kontrollgruppen, men gruppen besvarade i snitt ett mindre antal unika frågor.
Skillnaden i unika frågor besvarade mellan grupperna kan möjligen förklaras med Sana Learns strategi att välja ut frågor till användaren. Exakt vilken strategi Sana Learn använder är okänt men ett exempel på en sådan tänkbar strategi är att algoritmen delar in frågorna i segment. Dessa segment med nya frågor presenteras till användaren succesivt vartefter användaren lär sig ord från det tidigare segmentet. Med en sådan strategi så behöver användaren besvara samma fråga ett flertal gånger tills att Sana Learn bedömer att den är inlärd. I kontrast så har svaren för användarna i kontrollgruppen ingen påverkan på näst kommande frågor, utan dessa tilldelades slumpmässigt.
Skillnaden i unika frågor besvarade kan också förklara skillnaden mellan testresultaten över tid för de båda grupperna. Resultaten för grupp ”maskininlärning” ökar stabilt över tiden jämfört med kontrollgruppen där resultaten skiftar mer över tid. Förutsatt att Sana Learn använder sig av en liknande strategi som presenterades ovan, med frågor ordnade i segment, så kommer användaren besvara liknande frågor i påföljande prov. Detta kan möjligtvis ha gett ”maskininlärnings” gruppens användare en större chans att lära sig frågorna jämfört med användare i kontrollgruppen, som troligtvis kommer stöta på okända frågor mycket oftare. Detta kan även förklara den stadigt ökande poängen med tiden för grupp ”maskininlärning”, eftersom de får en större chans att repetera frågor och blir presenterade nya frågor i lagom takt efter deras inlärningsförmåga.
Metoddiskussion
Metodens inverkan på resultatet
Baserat på resultaten kan grupp ”maskininlärning” argumenteras vara ”segraren” inom undersökningen, eftersom de presterade bäst utifrån de variabler som uppmättes. Men resultatet kan fortfarande diskuteras. Gruppen har förvisso presterat bättre men på en mindre andel av innehållet. Om vi skulle jämföra gruppernas resultat i ett reellt sammanhang där systemet skulle användas som till exempel i en skolmiljö, skulle vi fortfarande dra samma slutsats? Beroende på storleken av innehållet missar grupp ”maskininlärning” att träna på vissa områden. Samtidigt exponeras kontrollgruppen till en större del av innehållet men får inte samma chans till repetition. Vad som är att föredra beror på bedömningskriterierna för ämnet i fråga och strukturen av ämnets innehåll.
Möjligtvis kan en kombination av de båda strategierna visa sig vara mest effektivt. Slumpmässig sortering av frågor vid introduktion av ämnet, för att bygga upp en översiktlig men stark grundkunskap om ämnets olika delar, sedan användning av Sana Learn för att hjälpa den enskilde eleven att fördjupa sig ytterligare. Effektiviteten av en sådan ”hybrid” strategi skulle kunna evalueras ifall man gjorde undersökningen på nytt med en tredje testgrupp, som fick frågor tilldelade slumpmässigt i början av testperioden och efter tidens gång fler frågor utvalda av Sana Learn.
Valet av inlärningsmaterial
Valet av grönländska glosor som innehåll till undersökningen kan också diskuteras. Ett rekommendationssystems framgång baseras till stor del efter hur väl den kan relatera användaren till innehållet. Från Sana Labs tekniska dokumentation vet vi att Sana Learn modellerar innehållet efter flera faktorer inklusive Innehållslikhet (”Content Similarity”, se Bild 5) och Automatisk Innehållstagning (”Automatic Content Tagging”, se Bild 5). Automatisk innehållstagning försöker kategorisera innehåll med taggar som beskriver innehållet som till exempel ”Matte 5”, ”Polynom Division” etcetera. Innehållslikhet försöker gruppera liknande frågor efter likhet med hjälp av de taggar de blivit kategoriserade efter.
Frågan är hur väl grönländska glosor kunde kategoriseras och ifall det gav Sana Learn en fungerande grund för att utföra rekommendationer. Det är möjligt att andra resultat hade uppnåtts ifall undersökningen utfördes på nytt med ett annat ämne som till exempel matematik. Ord kan kategoriseras in i ordklasser, singular eller plural etcetera men dessa egenskaper hos ord har en relativ låg inverkan på dess inlärningssvårighet. Uppgifter inom ett ämne som till exempel matematik kan tydligare kategoriseras efter olika svårighetsområden för en användare, till exempel ”Trigonometri”, ”Algebra”, ”Grafer” etcetera.
Eftersom testpersonerna saknade förkunskaper inom grönländska så bidrog valet till jämnare förutsättningar inför undersökningen. Men även fast innehållet minimerade felkällor så speglar det inte de reella förhållandena som system skulle användas under. I de allra flesta fall baseras akademiska kurser på förkunskaper, valet att introducera ett främmande ämne kan ha avskräckt testpersoner som i vanliga fall hade visat ett större engagemang.
Spridning i resultatet
För variabeln ”slutförda test” användes en median istället för ett medelvärde. Anledningen bakom detta var den stora spridningen inom antalet test gjorda i grupper, spridningen var speciellt stor inom kontrollgruppen där flera gjorde inga test alls medan andra genomförde tiotals test. Därför gav en median ett mera representativt värde än ett medelvärde på antalet test för de användare som regelbundet utförde test.
Med tanke på den stora spridningen inom antalet slutförda test så kan man ställa sig emot beslutet att låta användarna disponera tiden fritt. Eftersom det inte fanns någon slutgiltig prövning eller krav på användarna, så kan man argumentera att undersökningen misslyckades skapa de reella förhållandena som systemet i praktik skulle användas under. Å andra sidan så ledde beslutet till att undersökningen gav en bild av de två gruppernas olika engagemangsnivåer, i vilket det visade sig finnas en märkbar skillnad. Ifall undersökningen genomförs på nytt kan införandet av en slutgiltig prövning skapa ett mera autentiskt resultat.
Framtiden
Maskininlärning inom utbildning har flera utvecklingsområden där det finns potential för utbredning i framtiden. Ett exempel på ett sådant område är elevdiagnostik. Ifall eleverna studerar ett ämnesområde på en nätplattform som sammankopplar eleverna till en klassgrupp, så finns möjligheten att med hjälp av maskininlärning rekommendera svårighetsområden för klassen till läraren som kan ta hjälp av det på lektionerna.
Det finns dock problem som kan uppstå ifall maskininlärning integreras på en större skala inom våra utbildningssystem. Maskininlärningsalgoritmers objektivitet kan leda till problem inom till exempel elevdiagnostik. Ifall det ”teoretiska” systemet rekommenderar svårighetsområden efter hur ofta elever svarar fel på frågor inom området, så kan systemet missa områden som elever inte har besvarat frågor på. Eftersom det har skett mindre felaktiga svar jämfört med ämnen som elever är mera ”aktiva” inom.
Maskininlärningsalgoritmernas objektivitet kan också leda till att systemen missar den mänskliga egenskapen att glömma. Ifall systemet bedömer att en fråga eller ett område är inlärt och slutar presentera vissa frågor, så ökar chansen att användaren glömmer bort. En lösning på detta problem kan vara att införa vissa ”slumpmässiga” frågor som testar användaren på frågor den redan lärt sig.
Integritet
Frågan om integritet är viktig inom datorsystem generellt men argumenterbart mera så med maskininlärningssystem. Den data som används inom systemet kommer vid flera skeden inte vara anonym, eftersom de måste kunna anknytas till en användare för att hjälpa vid inlärning. Ur ett samhällsperspektiv kan det uppstå integritetsproblem eftersom skolor samlar in data om elever, som i stora drag kommer vara minderåriga. Ifall omfattande integrationer sker bör det implementeras som ett komplement till skolgången, så eleverna blir presenterade valet att använda det eller inte, likt hur skolor måste be om tillåtelse från elever för att publicera bilder av dem på internetet.
Slutsats
Slutsatsen av undersökningen är att maskininlärning har haft en positiv inverkan på testpersonernas prestation. Grupp ”maskininlärning” hade ett större driv, utförde fler test och presterade i snitt bättre än kontrollgruppen, men på ett mindre antal unika frågor. Denna skillnad i besvarade unika frågor kan leda till ett missvisande resultat. Vilket kräver ett mer omfattande test för att utreda hur lång tid det tar tills att grupp ”maskininlärning” och kontrollgruppen besvarar samma mängd unika frågor.
Referenser
Anyoha, R. (den 28 8 2017). The History of Artificial Intelligence . [Blog] The History of Artificial Intelligence . Harvard University. Hämtat från The History of Artificial Intelligence [Blog]: http://sitn.hms.harvard.edu/flash/2017/history-artificial-intelligence/
Compello. (den 18 10 2019). Maskininlärning. Hämtat från compello.com: https://www.compello.com/se/ordbok/maskininlarning/
George A. Sielis, A. T. (u.å). Recommender System Review: Types, Techniques and Applications. Hämtat från cs.ucy.ac.cy: https://www.cs.ucy.ac.cy/~george/files/IGI15.pdf
Google AI defeats human Go champion. (den 25 5 2017). Hämtat från BBC: https://www.bbc.com/news/technology-40042581
Google Developers. (den 27 9 2019). Matrix Factorization. Hämtat från developers.google.com: https://developers.google.com/machine-learning/recommendation/collaborative/matrix
Hagsten, A. (den 6 4 2017). [Blog] Maskininlärning med ett neuralt nätverk i C# - Del 1 - Teorin. Hämtat från InfoZone: https://www.infozone.se/blog/2017/04/06/maskininlarning-med-ett-neuralt-natverk-i-c-del-1-teorin/
Jeffcock, P. (den 11 7 2018). What’s the Difference Between AI, Machine Learning, and Deep Learning? Hämtat från Oracle: https://blogs.oracle.com/bigdata/difference-ai-machine-learning-deep-learning
Koskelainen, A. (den 10 4 2017). Kinesiska världsettan i Go blir nästa utmaning för Googles AI-spelare. Hämtat från IDG.se: https://www.idg.se/2.1085/1.680259/google-go-ai-alpha-go
Laerd Statistics . (den 14 2 2020). Linear Regression Analysis using SPSS Statistics. Hämtat från Laerd Statistics : https://statistics.laerd.com/spss-tutorials/linear-regression-using-spss-statistics.php
Lindgren & Ivarsson, J. M. (den 11 4 2016). Movie recommendations using matrix factorization. Hämtat från kth.se: http://www.diva-portal.org/smash/get/diva2:927190/FULLTEXT01.pdf
Lubeck, J. (den 1 3 2014). Linär regression och stokastiska vektorer. Hämtat från maths.lth.se: http://www.maths.lth.se/matstat/kurser/fms012/f/fant/regression.pdf
Malmgren, H. (den 26 1 2003). Artificiella Neurala Nätverk: en kort introduktion . Hämtat från phil.gu.se: http://www.phil.gu.se/ann/annintr.html
Markoff, J. (den 16 2 2011). Computer Wins on ‘Jeopardy!’: Trivial, It’s Not. Hämtat från The New York Times: https://www.nytimes.com/2011/02/17/science/17jeopardy-watson.html
Nicholson, C. (den 14 2 2020). A Beginner’s Guide to Neural Networks and Deep Learning. Hämtat från pathmind: https://pathmind.com/wiki/neural-network
Petterson, P. (u.å). Matristeori. Hämtat från maths.lth.se: http://www.maths.lth.se/matematiklth/personal/ah/Matris08/allm.pdf
Sana Labs. (den 13 9 2019). sanalabs.com. Hämtat från about: https://sanalabs.com/about/
Sana Labs. (den 27 1 2020). Sana Learn Technology. Hämtat från Sana Learn: https://sanalabs.com/developer/sana-learn/technology/
Serrano, L. (den 7 9 2018). How does Netflix recommend movies? Matrix Factorization. Hämtat från youtube.com: https://www.youtube.com/watch?v=ZspR5PZemcs
Sewaqu. (den 31 3 2016). File:Linear regression.svg. Hämtat från Wikimedia Commons: https://commons.wikimedia.org/wiki/File:Linear_regression.svg
Sollinger, M. (den 5 1 2018). Garry Kasparov and the game of artificial intelligence. Hämtat från pri.org: https://www.pri.org/stories/2018-01-05/ garry-kasparov-and-game-artificial-intelligence
Turing. (den 6 9 2019). Hämtat från Merriam Webster: https://www.merriam-webster.com/dictionary/Turing%20test
Turing, A. (1950). University of Maryland. Hämtat från https://www.csee.umbc.edu/courses/471/papers/turing.pdf
Bilaga 1
Källkoden i sin helhet: https://github.com/jollescott/mimer
Bilaga 2
Källkoden i sin helhet: https://github.com/jollescott/sana-python